利用python爬取豆瓣电影Top250的相关信息,包括电影详情链接,图片链接,影片中文名,影片外国名,评分,评价数,概况,导演,主演,年份,地区,类别这12项内容,然后将爬取的信息写入Excel表中。基本上爬取结果还是挺好的。具体代码如下:
#!/usr/bin/python
#-*- coding: utf-8 -*-
import sys
reload(sys)
sys.setdefaultencoding('utf8')
from bs4 import BeautifulSoup
import re
import urllib2
import xlwt
#得到页面全部内容
def askURL(url):
request = urllib2.Request(url)#发送请求
try:
response = urllib2.urlopen(request)#取得响应
html= response.read()#获取网页内容
#print html
except urllib2.URLError, e:
if hasattr(e,"code"):
print e.code
if hasattr(e,"reason"):
print e.reason
return html
#获取相关内容
def getData(baseurl):
findLink=re.compile(r'<a href="(.*" rel="external nofollow" >')#找到影片详情链接
findImgSrc=re.compile(r'<img.*src="/UploadFiles/2021-04-08/(.*jpg)">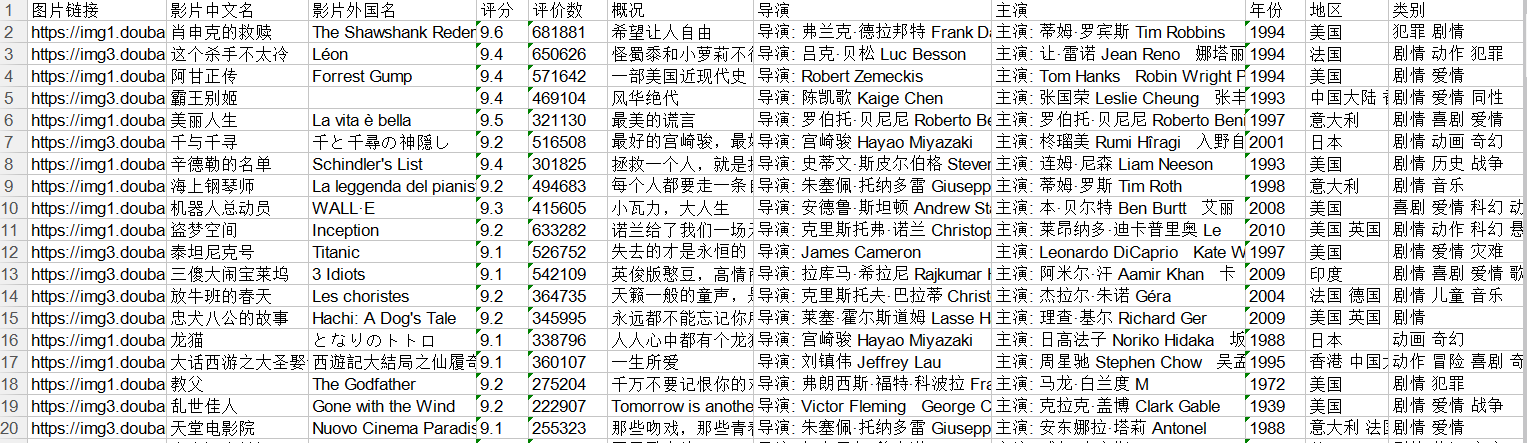
以上所述是小编给大家介绍的Python爬取豆瓣电影Top250实例详解整合,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对网站的支持!

华山资源网 Design By www.eoogi.com
广告合作:本站广告合作请联系QQ:858582 申请时备注:广告合作(否则不回)
免责声明:本站资源来自互联网收集,仅供用于学习和交流,请遵循相关法律法规,本站一切资源不代表本站立场,如有侵权、后门、不妥请联系本站删除!
免责声明:本站资源来自互联网收集,仅供用于学习和交流,请遵循相关法律法规,本站一切资源不代表本站立场,如有侵权、后门、不妥请联系本站删除!
华山资源网 Design By www.eoogi.com
暂无评论...
《魔兽世界》大逃杀!60人新游玩模式《强袭风暴》3月21日上线
暴雪近日发布了《魔兽世界》10.2.6 更新内容,新游玩模式《强袭风暴》即将于3月21 日在亚服上线,届时玩家将前往阿拉希高地展开一场 60 人大逃杀对战。
艾泽拉斯的冒险者已经征服了艾泽拉斯的大地及遥远的彼岸。他们在对抗世界上最致命的敌人时展现出过人的手腕,并且成功阻止终结宇宙等级的威胁。当他们在为即将于《魔兽世界》资料片《地心之战》中来袭的萨拉塔斯势力做战斗准备时,他们还需要在熟悉的阿拉希高地面对一个全新的敌人──那就是彼此。在《巨龙崛起》10.2.6 更新的《强袭风暴》中,玩家将会进入一个全新的海盗主题大逃杀式限时活动,其中包含极高的风险和史诗级的奖励。
《强袭风暴》不是普通的战场,作为一个独立于主游戏之外的活动,玩家可以用大逃杀的风格来体验《魔兽世界》,不分职业、不分装备(除了你在赛局中捡到的),光是技巧和战略的强弱之分就能决定出谁才是能坚持到最后的赢家。本次活动将会开放单人和双人模式,玩家在加入海盗主题的预赛大厅区域前,可以从强袭风暴角色画面新增好友。游玩游戏将可以累计名望轨迹,《巨龙崛起》和《魔兽世界:巫妖王之怒 经典版》的玩家都可以获得奖励。
更新日志
2024年11月17日
2024年11月17日
- 【雨果唱片】中国管弦乐《鹿回头》WAV
- APM亚流新世代《一起冒险》[FLAC/分轨][106.77MB]
- 崔健《飞狗》律冻文化[WAV+CUE][1.1G]
- 罗志祥《舞状元 (Explicit)》[320K/MP3][66.77MB]
- 尤雅.1997-幽雅精粹2CD【南方】【WAV+CUE】
- 张惠妹.2007-STAR(引进版)【EMI百代】【WAV+CUE】
- 群星.2008-LOVE情歌集VOL.8【正东】【WAV+CUE】
- 罗志祥《舞状元 (Explicit)》[FLAC/分轨][360.76MB]
- Tank《我不伟大,至少我能改变我。》[320K/MP3][160.41MB]
- Tank《我不伟大,至少我能改变我。》[FLAC/分轨][236.89MB]
- CD圣经推荐-夏韶声《谙2》SACD-ISO
- 钟镇涛-《百分百钟镇涛》首批限量版SACD-ISO
- 群星《继续微笑致敬许冠杰》[低速原抓WAV+CUE]
- 潘秀琼.2003-国语难忘金曲珍藏集【皇星全音】【WAV+CUE】
- 林东松.1997-2039玫瑰事件【宝丽金】【WAV+CUE】