目标函数

编码方式
本程序采用的是二进制编码精确到小数点后五位,经过计算可知对于  其编码长度为18,对于
其编码长度为18,对于 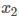 其编码长度为15,因此每个基于的长度为33。
其编码长度为15,因此每个基于的长度为33。
参数设置

算法步骤
设计的程序主要分为以下步骤:1、参数设置;2、种群初始化;3、用轮盘赌方法选择其中一半较好的个体作为父代;4、交叉和变异;5、更新最优解;6、对最有个体进行自学习操作;7结果输出。其算法流程图为:

算法结果
由程序输出可知其最终优化结果为38.85029, 
输出基因编码为[1 1 0 0 1 0 1 1 1 1 1 1 1 0 1 1 1 1 0 1 0 1 1 0 1 0 0 1 0 1 1 1 1]。
代码
import numpy as np
import random
import math
import copy
class Ind():
def __init__(self):
self.fitness = 0
self.x = np.zeros(33)
self.place = 0
self.x1 = 0
self.x2 = 0
def Cal_fit(x, upper, lower): #计算适应度值函数
Temp1 = 0
for i in range(18):
Temp1 += x[i] * math.pow(2, i)
Temp2 = 0
for i in range(18, 33, 1):
Temp2 += math.pow(2, i - 18) * x[i]
x1 = lower[0] + Temp1 * (upper[0] - lower[0])/(math.pow(2, 18) - 1)
x2 = lower[1] + Temp2 * (upper[1] - lower[1])/(math.pow(2, 15) - 1)
if x1 > upper[0]:
x1 = random.uniform(lower[0], upper[0])
if x2 > upper[1]:
x2 = random.uniform(lower[1], upper[1])
return 21.5 + x1 * math.sin(4 * math.pi * (x1)) + x2 * math.sin(20 * math.pi * x2)
def Init(G, upper, lower, Pop): #初始化函数
for i in range(Pop):
for j in range(33):
G[i].x[j] = random.randint(0, 1)
G[i].fitness = Cal_fit(G[i].x, upper, lower)
G[i].place = i
def Find_Best(G, Pop):
Temp = copy.deepcopy(G[0])
for i in range(1, Pop, 1):
if G[i].fitness > Temp.fitness:
Temp = copy.deepcopy(G[i])
return Temp
def Selection(G, Gparent, Pop, Ppool): #选择函数
fit_sum = np.zeros(Pop)
fit_sum[0] = G[0].fitness
for i in range(1, Pop, 1):
fit_sum[i] = G[i].fitness + fit_sum[i - 1]
fit_sum = fit_sum/fit_sum.max()
for i in range(Ppool):
rate = random.random()
Gparent[i] = copy.deepcopy(G[np.where(fit_sum > rate)[0][0]])
def Cross_and_Mutation(Gparent, Gchild, Pc, Pm, upper, lower, Pop, Ppool): #交叉和变异
for i in range(Ppool):
place = random.sample([_ for _ in range(Ppool)], 2)
parent1 = copy.deepcopy(Gparent[place[0]])
parent2 = copy.deepcopy(Gparent[place[1]])
parent3 = copy.deepcopy(parent2)
if random.random() < Pc:
num = random.sample([_ for _ in range(1, 32, 1)], 2)
num.sort()
if random.random() < 0.5:
for j in range(num[0], num[1], 1):
parent2.x[j] = parent1.x[j]
else:
for j in range(0, num[0], 1):
parent2.x[j] = parent1.x[j]
for j in range(num[1], 33, 1):
parent2.x[j] = parent1.x[j]
num = random.sample([_ for _ in range(1, 32, 1)], 2)
num.sort()
num.sort()
if random.random() < 0.5:
for j in range(num[0], num[1], 1):
parent1.x[j] = parent3.x[j]
else:
for j in range(0, num[0], 1):
parent1.x[j] = parent3.x[j]
for j in range(num[1], 33, 1):
parent1.x[j] = parent3.x[j]
for j in range(33):
if random.random() < Pm:
parent1.x[j] = (parent1.x[j] + 1) % 2
if random.random() < Pm:
parent2.x[j] = (parent2.x[j] + 1) % 2
parent1.fitness = Cal_fit(parent1.x, upper, lower)
parent2.fitness = Cal_fit(parent2.x, upper, lower)
Gchild[2 * i] = copy.deepcopy(parent1)
Gchild[2 * i + 1] = copy.deepcopy(parent2)
def Choose_next(G, Gchild, Gsum, Pop): #选择下一代函数
for i in range(Pop):
Gsum[i] = copy.deepcopy(G[i])
Gsum[2 * i + 1] = copy.deepcopy(Gchild[i])
Gsum = sorted(Gsum, key = lambda x: x.fitness, reverse = True)
for i in range(Pop):
G[i] = copy.deepcopy(Gsum[i])
G[i].place = i
def Decode(x): #解码函数
Temp1 = 0
for i in range(18):
Temp1 += x[i] * math.pow(2, i)
Temp2 = 0
for i in range(18, 33, 1):
Temp2 += math.pow(2, i - 18) * x[i]
x1 = lower[0] + Temp1 * (upper[0] - lower[0]) / (math.pow(2, 18) - 1)
x2 = lower[1] + Temp2 * (upper[1] - lower[1]) / (math.pow(2, 15) - 1)
if x1 > upper[0]:
x1 = random.uniform(lower[0], upper[0])
if x2 > upper[1]:
x2 = random.uniform(lower[1], upper[1])
return x1, x2
def Self_Learn(Best, upper, lower, sPm, sLearn): #自学习操作
num = 0
Temp = copy.deepcopy(Best)
while True:
num += 1
for j in range(33):
if random.random() < sPm:
Temp.x[j] = (Temp.x[j] + 1)%2
Temp.fitness = Cal_fit(Temp.x, upper, lower)
if Temp.fitness > Best.fitness:
Best = copy.deepcopy(Temp)
num = 0
if num > sLearn:
break
return Best
if __name__ == '__main__':
upper = [12.1, 5.8]
lower = [-3, 4.1]
Pop = 100
Ppool = 50
G_max = 300
Pc = 0.8
Pm = 0.1
sPm = 0.05
sLearn = 20
G = np.array([Ind() for _ in range(Pop)])
Gparent = np.array([Ind() for _ in range(Ppool)])
Gchild = np.array([Ind() for _ in range(Pop)])
Gsum = np.array([Ind() for _ in range(Pop * 2)])
Init(G, upper, lower, Pop) #初始化
Best = Find_Best(G, Pop)
for k in range(G_max):
Selection(G, Gparent, Pop, Ppool) #使用轮盘赌方法选择其中50%为父代
Cross_and_Mutation(Gparent, Gchild, Pc, Pm, upper, lower, Pop, Ppool) #交叉和变异生成子代
Choose_next(G, Gchild, Gsum, Pop) #选择出父代和子代中较优秀的个体
Cbest = Find_Best(G, Pop)
if Best.fitness < Cbest.fitness:
Best = copy.deepcopy(Cbest) #跟新最优解
else:
G[Cbest.place] = copy.deepcopy(Best)
Best = Self_Learn(Best, upper, lower, sPm, sLearn)
print(Best.fitness)
x1, x2 = Decode(Best.x)
print(Best.x)
print([x1, x2])
以上这篇Python实现遗传算法(二进制编码)求函数最优值方式就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持。
华山资源网 Design By www.eoogi.com
广告合作:本站广告合作请联系QQ:858582 申请时备注:广告合作(否则不回)
免责声明:本站资源来自互联网收集,仅供用于学习和交流,请遵循相关法律法规,本站一切资源不代表本站立场,如有侵权、后门、不妥请联系本站删除!
免责声明:本站资源来自互联网收集,仅供用于学习和交流,请遵循相关法律法规,本站一切资源不代表本站立场,如有侵权、后门、不妥请联系本站删除!
华山资源网 Design By www.eoogi.com
暂无评论...
苹果官宣WWDC 2024!预计会有大批AI功能 - 2024/11/16
3月27日消息,苹果宣布2024年全球开发者大会(WWDC)将于6月10日至6月14日举行,巧合的是,这次大会与端午假期重合。
苹果官方表示:
在线参加 Apple 每年规模最大的开发者盛会。亲眼见证 Apple 最新平台、技术和工具的发布。了解如何创建和改进你的 App 和游戏。与 Apple 设计师和工程师互动交流,与全球开发者社区建立联系。以上活动均免费在线举行。
探索各种新的工具、框架和功能,助力你打造出理想的 App 和游戏。通过视频讲座学习新技能,与 Apple 专家进行一对一会面,以推进你的项目,完善你的构思。
Swift Student Challenge 旨在支持和鼓舞下一代开发者、创作者和企业家。太平洋时间 3 月 28 日,我们将公布今年的获奖者名单。获奖者将有资格参加在 Apple Park 举办的特别活动。我们还会选出 50 名杰出获胜者,他们将受邀前往库比提诺,获得为期三天的非凡体验,包括参加 Apple Park 的特别活动。
3月27日消息,苹果宣布2024年全球开发者大会(WWDC)将于6月10日至6月14日举行,巧合的是,这次大会与端午假期重合。
苹果官方表示:
在线参加 Apple 每年规模最大的开发者盛会。亲眼见证 Apple 最新平台、技术和工具的发布。了解如何创建和改进你的 App 和游戏。与 Apple 设计师和工程师互动交流,与全球开发者社区建立联系。以上活动均免费在线举行。
探索各种新的工具、框架和功能,助力你打造出理想的 App 和游戏。通过视频讲座学习新技能,与 Apple 专家进行一对一会面,以推进你的项目,完善你的构思。
Swift Student Challenge 旨在支持和鼓舞下一代开发者、创作者和企业家。太平洋时间 3 月 28 日,我们将公布今年的获奖者名单。获奖者将有资格参加在 Apple Park 举办的特别活动。我们还会选出 50 名杰出获胜者,他们将受邀前往库比提诺,获得为期三天的非凡体验,包括参加 Apple Park 的特别活动。
RTX 5090要首发 性能要翻倍!三星展示GDDR7显存
三星在GTC上展示了专为下一代游戏GPU设计的GDDR7内存。
首次推出的GDDR7内存模块密度为16GB,每个模块容量为2GB。其速度预设为32 Gbps(PAM3),但也可以降至28 Gbps,以提高产量和初始阶段的整体性能和成本效益。
据三星表示,GDDR7内存的能效将提高20%,同时工作电压仅为1.1V,低于标准的1.2V。通过采用更新的封装材料和优化的电路设计,使得在高速运行时的发热量降低,GDDR7的热阻比GDDR6降低了70%。
更新日志
2024年11月16日
2024年11月16日
- 群星《2024好听新歌36》AI调整音效【WAV分轨】
- 梁朝伟.1986-朦胧夜雨裡(华星40经典)【华星】【WAV+CUE】
- 方芳.1996-得意洋洋【中唱】【WAV+CUE】
- 辛欣.2001-放120个心【上海音像】【WAV+CUE】
- 柏菲·万山红《花开原野1》限量开盘母带ORMCD[低速原抓WAV+CUE]
- 柏菲·万山红《花开原野2》限量开盘母带ORMCD[低速原抓WAV+CUE]
- 潘安邦《思念精选集全纪录》5CD[WAV+CUE]
- 杨千嬅《千嬅新唱金牌金曲》金牌娱乐 [WAV+CUE][985M]
- 杨钰莹《依然情深》首版[WAV+CUE][1G]
- 第五街的士高《印度激情版》3CD [WAV+CUE][2.4G]
- 三国志8重制版哪个武将智力高 三国志8重制版智力武将排行一览
- 三国志8重制版哪个武将好 三国志8重制版武将排行一览
- 三国志8重制版武将图像怎么保存 三国志8重制版武将图像设置方法
- 何方.1990-我不是那种人【林杰唱片】【WAV+CUE】
- 张惠妹.1999-妹力新世纪2CD【丰华】【WAV+CUE】