相比于2018年,在ICLR2019提交论文中,提及不同框架的论文数量发生了极大变化,网友发现,提及tensorflow的论文数量从2018年的228篇略微提升到了266篇,keras从42提升到56,但是pytorch的数量从87篇提升到了252篇。
TensorFlow: 228--->266
Keras: 42--->56
Pytorch: 87--->252
在使用pytorch中,自己有一些思考,如下:
1. loss计算和反向传播
import torch.nn as nn criterion = nn.MSELoss().cuda() output = model(input) loss = criterion(output, target) loss.backward()
通过定义损失函数:criterion,然后通过计算网络真实输出和真实标签之间的误差,得到网络的损失值:loss;
最后通过loss.backward()完成误差的反向传播,通过pytorch的内在机制完成自动求导得到每个参数的梯度。
需要注意,在机器学习或者深度学习中,我们需要通过修改参数使得损失函数最小化或最大化,一般是通过梯度进行网络模型的参数更新,通过loss的计算和误差反向传播,我们得到网络中,每个参数的梯度值,后面我们再通过优化算法进行网络参数优化更新。
2. 网络参数更新
在更新网络参数时,我们需要选择一种调整模型参数更新的策略,即优化算法。
优化算法中,简单的有一阶优化算法:

其中 就是通常说的学习率,
就是通常说的学习率,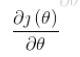 是函数的梯度;
是函数的梯度;
自己的理解是,对于复杂的优化算法,基本原理也是这样的,不过计算更加复杂。
在pytorch中,torch.optim是一个实现各种优化算法的包,可以直接通过这个包进行调用。
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
注意:
1)在前面部分1中,已经通过loss的反向传播得到了每个参数的梯度,然后再本部分通过定义优化器(优化算法),确定了网络更新的方式,在上述代码中,我们将模型的需要更新的参数传入优化器。
2)注意优化器,即optimizer中,传入的模型更新的参数,对于网络中有多个模型的网络,我们可以选择需要更新的网络参数进行输入即可,上述代码,只会更新model中的模型参数。对于需要更新多个模型的参数的情况,可以参考以下代码:
optimizer = torch.optim.Adam([{'params': model.parameters()}, {'params': gru.parameters()}], lr=0.01) 3) 在优化前需要先将梯度归零,即optimizer.zeros()。
3. loss计算和参数更新
import torch.nn as nn import torch criterion = nn.MSELoss().cuda() optimizer = torch.optim.Adam(model.parameters(), lr=0.01) output = model(input) loss = criterion(output, target) optimizer.zero_grad() # 将所有参数的梯度都置零 loss.backward() # 误差反向传播计算参数梯度 optimizer.step() # 通过梯度做一步参数更新
以上这篇关于pytorch中网络loss传播和参数更新的理解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持。
免责声明:本站资源来自互联网收集,仅供用于学习和交流,请遵循相关法律法规,本站一切资源不代表本站立场,如有侵权、后门、不妥请联系本站删除!
3月27日消息,苹果宣布2024年全球开发者大会(WWDC)将于6月10日至6月14日举行,巧合的是,这次大会与端午假期重合。
苹果官方表示:
在线参加 Apple 每年规模最大的开发者盛会。亲眼见证 Apple 最新平台、技术和工具的发布。了解如何创建和改进你的 App 和游戏。与 Apple 设计师和工程师互动交流,与全球开发者社区建立联系。以上活动均免费在线举行。
探索各种新的工具、框架和功能,助力你打造出理想的 App 和游戏。通过视频讲座学习新技能,与 Apple 专家进行一对一会面,以推进你的项目,完善你的构思。
Swift Student Challenge 旨在支持和鼓舞下一代开发者、创作者和企业家。太平洋时间 3 月 28 日,我们将公布今年的获奖者名单。获奖者将有资格参加在 Apple Park 举办的特别活动。我们还会选出 50 名杰出获胜者,他们将受邀前往库比提诺,获得为期三天的非凡体验,包括参加 Apple Park 的特别活动。
RTX 5090要首发 性能要翻倍!三星展示GDDR7显存
三星在GTC上展示了专为下一代游戏GPU设计的GDDR7内存。
首次推出的GDDR7内存模块密度为16GB,每个模块容量为2GB。其速度预设为32 Gbps(PAM3),但也可以降至28 Gbps,以提高产量和初始阶段的整体性能和成本效益。
据三星表示,GDDR7内存的能效将提高20%,同时工作电压仅为1.1V,低于标准的1.2V。通过采用更新的封装材料和优化的电路设计,使得在高速运行时的发热量降低,GDDR7的热阻比GDDR6降低了70%。
更新日志
- 纪钧瀚《钢琴阅读时光 雨中书店聆听轻音乐》[FLAC/分轨][399.62MB]
- 证声音乐图书馆《走向自然 疗心爵士乐》[320K/MP3][87.4MB]
- 证声音乐图书馆《走向自然 疗心爵士乐》[FLAC/分轨][184.94MB]
- 陈慧娴.2018-Priscilla-Ism演唱会3CD(2024环球红馆40复刻系列)【环球】【WAV+CUE】
- 郑秀文.1999-我应该得到(国)【华纳】【WAV+CUE】
- 陈家慧.2011-钢琴酒吧2CD【龙吟唱片】【WAV+CUE】
- 证声音乐图书馆《雨季 蓝调吉他 Rainy Blues》[320K/MP3][45.01MB]
- 证声音乐图书馆《雨季 蓝调吉他 Rainy Blues》[FLAC/分轨][109.13MB]
- 赞多《序章》[320K/MP3][45.54MB]
- 许巍.2004-每一刻都是崭新的【步升大风】【WAV+CUE】
- 群星.2024-四方馆影视原声带【韶愔音乐】【FLAC分轨】
- 陈雷.1997-安锁咧【金圆唱片】【WAV+CUE】
- 关淑怡.2013-MY.FAVORITE.SK.3CD【环球】【WAV+CUE】
- Sweety.2006-花言乔语【丰华】【WAV+CUE】
- 李恕权.2003-回·20年全精选2CD【SONY】【WAV+CUE】